The cloud is a great way to get started with AI/ML. The going rate is around $4/hr for a GPU instance. It might be all that you need, but if you need to maximize your personal hardware buget this is my guide to buiding workstation.
Price
I spent ~$1000 and you could get it even lower with the current deals. I decided on a AMD Ryzen 3700X, Nvidia 2060 Super, 32GB of RAM, and an NVME drive. I could connect all of this into a B450m motherboard so I didn't see any reason to spend more. I also include another SSD for Windows 10 and two HDDs for storing datasets.
CPU
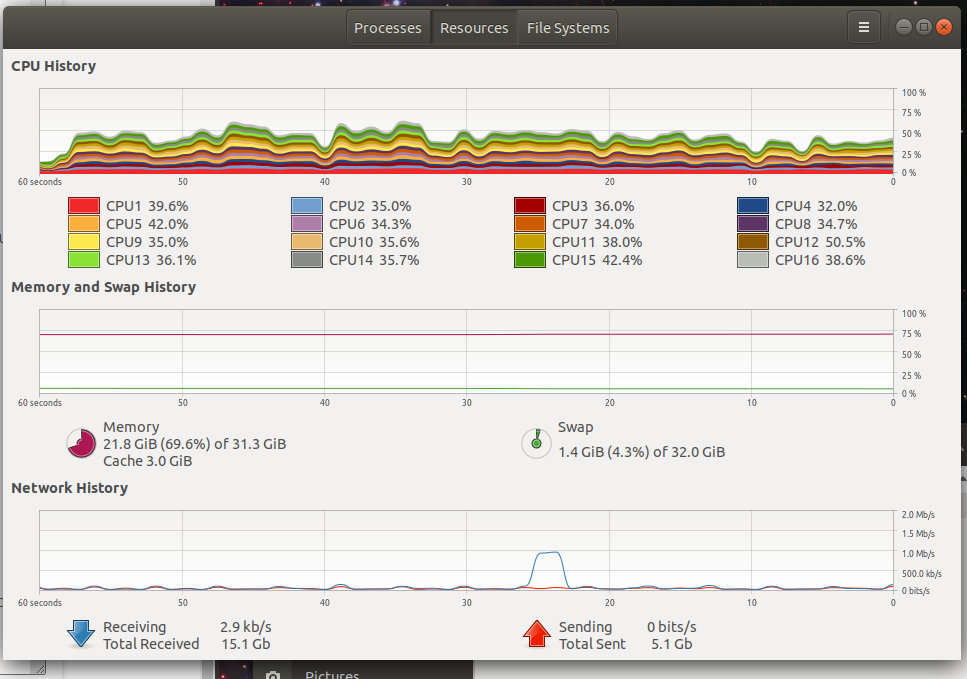
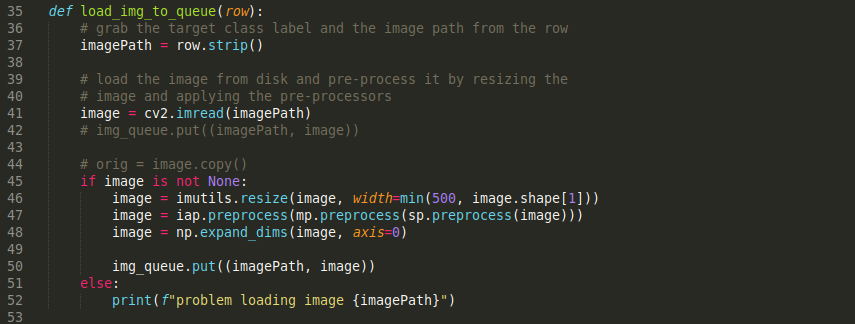
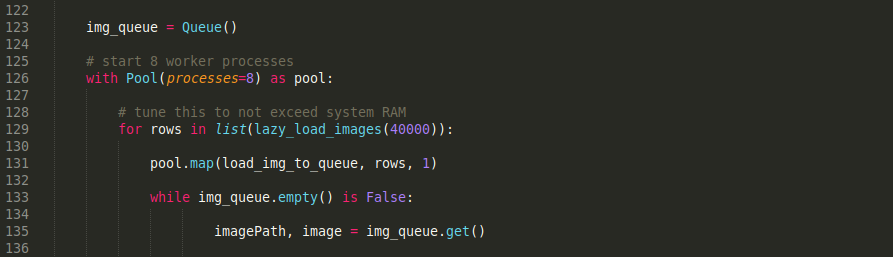
The Ryzen 3700x is far more than I need and most of the time several cores are idle. Because most of my tooling is in python it is a real struggle to make use of the resources. The multiprocess library is great and it isn't too complicated to make a Pool of CPU cores for the program to use.
GPU
The 2060 Super is in a very odd position in the current lineup. It is the cheapest model with 8GB of VRAM, to get 3GB more you have to 3x the price. It makes more sense to jump up to 24GB for 6x the price. Training CNN models on image data requires significant amounts of VRAM. You could spend more but without more VRAM the money would only provide marginal improvements due to the number of CUDA cores.
RAM
System memory is very similar to CPU cores, you will rarely max it out but it never hurts to have more available. I typically am using 20GB which means that I could reduce my batch size and be done with 16GB or I could just spend the extra $80 to get 32GB.
STORAGE
I'm using a 1TB NVME drive. It is very fast and tucks away nicely on the motherboard. It is overkill for my needs but it is nice to have the space to store millions of images and not wait on traditional HDDs.
Speaking of HDDs. I have two, a 1TB and a 2TB. The 1TB is just for datasets and so that I can keep space available on the faster drive. The second drive is for automatic backsups of the main disk and datasets. Backups are also doing to two different NASs but that is another blog post.
It would be a shame to have this machine and not play games on it. I'm using an inexpensive 1TB SSD for Windows 10. I don't like dual booting off of a single drive. I prefer using the bios boot selector to switch between OSes.
COOLING
The case I'm using has four 120mm fans. I added a giant Nactua heat sink with two additional 140mm fans. Adjust the motherboard fan curves so that everything is nice and quiet. I believe in having a lot of airflow and I haven't had any temperature problems (inside the case, the damn thing very noticably heats up my office).
UPGRADES
I'm currently happy with the way it is. The obvious upgrade will be for more GPU VRAM. I decided against water-cooling but if I get to a place with multiple GPUs that appears to be the best solution.