
Introduction
I wanted to know if the garage door is left open. This is how I trained my computer to text me when it has been open for too long.
Detecting if a garage door is open or closed is a surprisingly challenging problem. It is possible to do this with contact sensors or even with a motion (PIR) sensor, but that requires running additional wires and a controller.
My solution was to put a wireless IP camera to the ceiling. It connects to my home network using wifi and plugs into the same power outlet as the garage door opener.
Traditional video security analytics such as motion or line cross does not adequately detect the door being left open. Both motion and line cross depend on something happening to trigger. This is different because I am looking the position of the garage door instead of movement.
I also looked at a traditional computer vision solution to detect sunlight coming in through the open door. Ultimately trying to detect based on the 'brightness' of the scene would not work in this situation. The way the camera is position it would not be able to differential between the light from the ceiling and sunlight coming in through the garage door. This also would not work at night or during a storm. A different tool is needed.
I wanted to experiment with creating a machine learning model. This is a great first project to get start with.
The first large barrier to creating a machine learning model is the need for enough training data. It is common to hear about the burden of gathering and dealing with training data. I though I would need tens of thousands of images and it would be hours of classifying the images by hand. In the end I was able to train the model with a total of 400 images and I didn't even have to look at all of them.
Gathering the Images
The camera I am using records video. It is easy to think of video as a collection of individual frames. Each frame can be exported as an image. This means the camera is potentially producing 30 images per second at a 1920x1080 resolution. Having days of recorded video, I can use this to make gather images easy.
My security camera is connected through Eagle Eye Networks. Eagle Eye is a cloud based video security company with an open API. It makes it easy to retrieve images and videos. In addition to the HD video, the API automatically generate a lower resolution JPEG ever second. That is more than enough for this project.
Using their history browser I looked for spans of time when the door was closed and download that group of images. I also picked out ranges when the door was open. At one frame per second, I only needed a little over a three minute span to get the 200 hundred images I needed. Source code on Github
I got a list of the preview images using this API endpoint and then downloaded them with this API endpoint. I created zip folder of each batch of images to make the next step easier.
Using their history browser I looked for spans of time when the door was closed and download that group of images. I also picked out ranges when the door was open. At one frame per second, I only needed a little over a three minute span to get the 200 hundred images I needed. Source code on Github
You can highlight a section of time in the history browser by dropping two markers. Click anywhere on the timeline to drop a marker and then hold "shift" and click somewhere else. A highlighted section will show up as illustrated in the image below.
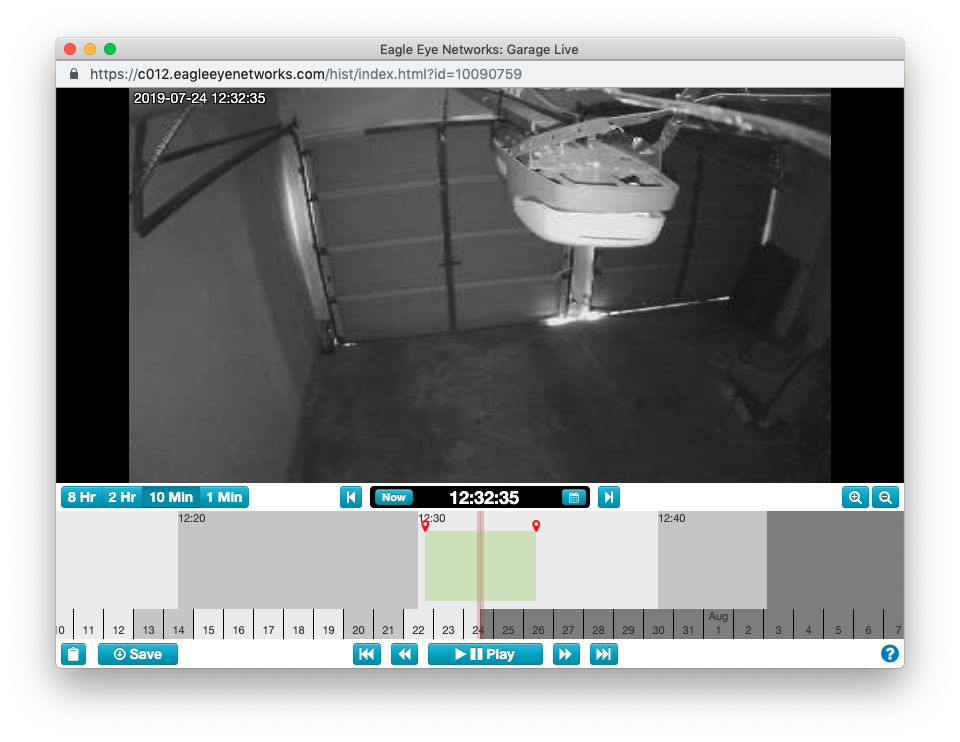
You can easily get the timestamps of the markers you selected by clicking on the clipboard icon in the lower left corner. It will copy a URL that contains the timestamps. It is formatted like this https://c012.eagleeyenetworks.com/#/camera_history/10090759/20190724173015.762/20190724173015.762/20190724173453.262 with 20190724173015.762 as the timestamp of the first marker and 20190724173453.262 as the timestamp of the second. The camera ID is 10090759 in the URL above.
With the camera ID, start and end timestamps you can get a list of preview images.I got a list of the preview images using this API endpoint and then downloaded them with this API endpoint. You can also use the included script named preview_downloader.py to automate the process. I created zip folder of each batch of images to make the next step easier.
Creating the Model
For my first model, I decided to use Google's AutoML tool to create the model. AutoML generates a TensorFlow that can be run in their cloud or downloaded and run locally. The easiest way to run it is inside of a docker container using their Docker image.
Every time the model is given an image it makes a prediction. The prediction is a confidence value for each label it was trained with. I want to get an answer from the model saying the door is open or closed. Because is a binary decision, I can just compare the two values and choose the one with the higher confidence value.
This problem is a great fit for image classification. We are able to provide sample images of both open and closed. When asking it to make predictions it is doing less guessing and more matching to what we trained it with.
For all the details you should read through Google's excellent tutorials. Creating this model was as easy as starting a new model, uploading the two zip files and letting it run. AutoML is smart enough to label all the images in a zip file the the name of the file itself. When the model is done generating, you can testing it in the AutoML tool. I recommend experimenting with additional training data if it doesn't get the predictions correct.
After you're confident in the accuracy of the model, you can use their hosted version or choose to generate an "Edge" model. I already am running servers so it was easier to download and run myself. Follow the instructions to download and run the model inside a Docker container. The tf_lite version of the model can run on mobile devices or even a Raspberry Pi.
Note:
If we wanted to pick out objects out of the image (people or cars or bicycles) we would want to change our strategy and use object detection instead of image classification. The amount of prep work and training data would increase because we would need to provide examples of each object in a variety of conditions. This is something I will experiment with in the future.
Connecting the Plumbing
The next step is to get images from the camrea in real-time. Eagle Eye has an events API that you can subscribe to and be notified everytime a new preview image is generated. Passing the model a preview image we can query our new model to get back the label predictions.
I've put the code on Github, but here are the highlights:
Subscribe to the Events API
ws = websocket.WebSocketApp('wss://login.eagleeyenetworks.com/api/v2/Device/{}/Events'.format(account_id),
cookie='auth_key={}'.format(auth_key),
on_message=on_message,
on_error=on_error,
on_close=on_close)For each event, get the preview image
url = "https://login.eagleeyenetworks.com/asset/asset/image.jpeg"
querystring = {"id": device_id, "timestamp": ts, "asset_class": "all" }
payload = ""
headers = { 'authorization': api_key }
response = session.request("GET", url, data=payload, params=querystring, headers=headers, timeout=5)After you have the image, pass it to container_predict
image_data = response.content
output = container_predict(image_data, ts)Check if it the garage door is open and send a SMS if it is
closed = output['predictions'][0]['scores'][0]
opened = output['predictions'][0]['scores'][1]
if opened >= closed:
message = "garage door is open [%s, %s]" % (opened, closed)
send_sms(message)and the SMS part
sms = twilio_client.messages.create(to="+15551234567", from_="+5551234567", body=message)Putting it all Together
I created a docker-compse.yaml file to launch the Tensorflow model and my python script.
version: '3'
services:
app:
build: .
volumes:
- .:/app
restart: always
stdin_open: true
tty: true
tensorflow:
image: gcr.io/automl-vision-ondevice/gcloud-container-1.12.0:latest
volumes:
- ./model/ICN7344367954367448370/2019-07-10_19-43-49-142_tf-saved-model/:/tmp/mounted_model/0001
ports:
- "8501:8501"
restart: alwaysand the individual Dockerfile
FROM python:3.7.2-slim
COPY ./requirements.txt /app/requirements.txt
WORKDIR /app
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
COPY . /app
CMD [ "./startup.sh" ]You can run the whole thing by bringing up the Docker containers
docker-compose up --build -dHow Well Does it Work
It is really good. Really, really good.
Here are two examples, the first is a normal use case and the second is intended to trick it. In both cases it gets the predictions correct.

For the second example it was able to correctly predict that the door stayed closed. I never trained it with people in the image and the door closed.

My theory of why it works so well, is that because it is such a simple image classification model. We could probably do the same thing by comparing each incoming image against the 400 images we used in a training set. Maybe apply a little gaussian blur to the images to soften the sharp edges.
Wrapping Up
I am really pleased with how this project turned out. Creating the model and get predictions was easier than expect. It was painless to connect it to the Eagle Eye API to get the images and then send SMS messages out through the Twilio API.
Now that I have it working, I am starting to look for more problems that can be solved using this same pattern.
Thanks for reading my experience and feel free to reach out to me with questions.