Machine learning has changed how I approach new programming tasks. I am going to be working through an example of detecting vehicles in a specific parking space. Traditionally this would be done by looking for motion inside of a specific ROI (region of interest). In this blog post I will be talking through achieving better results by focusing on dataset curation and machine learning.


The traditional way to detect a vehicle would be to try and catch it at a transition point, entering or exiting the frame. You could compare the video frames to see what has changed and if an object has entered or exiting the ROI. You could set up an expect minimum and maximum object size to improve accuracy and avoid false positive results..
Another way would be to look for known landmarks at known locations such as lines separating spaces or disabled vehicle symbol. This would involve some adjustment for scaling and skew but it could have a startup routine that was able to adapt to reasonable values for both. It wouldn't be detecting a vehicle, but there is a high probability that if the features are not visible then the spot is occupied. This should work at night by choosing features that have some degree of visibility at night or through rain.
A third technique could be similar to the previous example expect looking at the dominant color instead of specific features. This would not work at night when the camera switches to IR illumination and an IR filter. This sounds like a lazy option, but in specific circumstances it could perform quite well for looking for brown UPS vehicles that only make deliveries during daylight hours
In the traditional methods, you would look at the image with OpenCV and then operate on pixel data. Some assumptions would need to made on how individual pixels should be group together to form an object. The ROI would need to be defined. Care would also need to applied when handing how individual pixels create a specific feature, or are composed a color between our threshold values. All of this has been done before.
.The approach I am advocating for is to not program anything about the image at all. Each frame would be looked at and the model would make a prediction regardless of motion, features, or dominant colors. Such a general approach could easily be marketed as AI. I prefer to call it machine learning to clarify that the machine is doing the work and that it's only intelligence is in its ability to compare to known images. Think of it as a graph with a line that separates it into categories. The algorithm's only job is to predict where to place each image on the correct side of the line.
As more example images are added to the model, the line separating the groups of images changes to accomodate the complete dataset. If you are not careful to keep the two groups balanced than biases in the datasets can appear. Think of this as a simple programming bug.



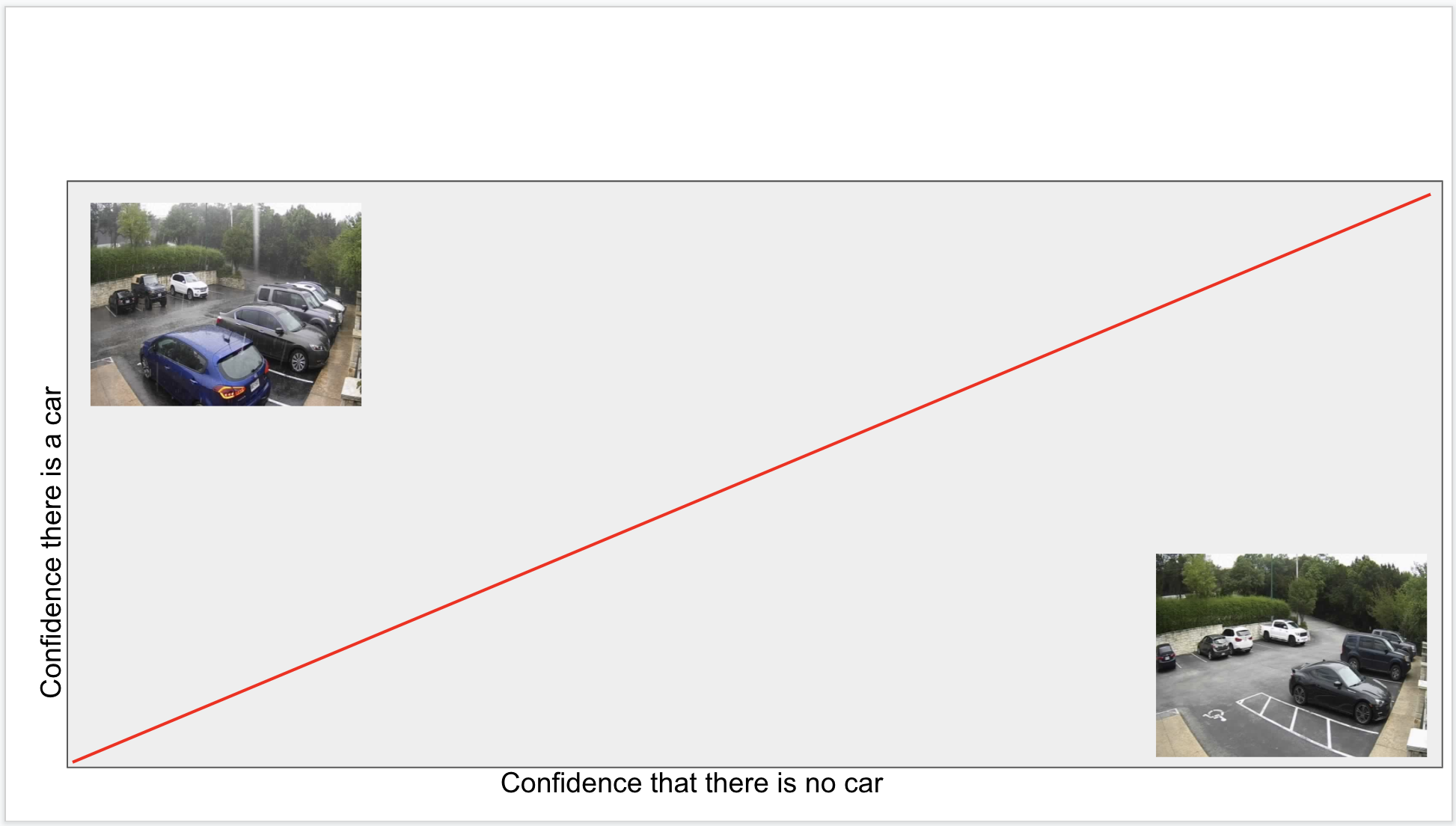
The first image is considered in the parking space, the second image is not. In both cases, the vehicle is blocking the parking space. The difference is arbitrary, but these special cases can be handled by including examples in the correct dataset. Think of what goes into the datasets as domain specific rules.



It is easy to build a dataset based on images evenly spaced through the day. Doing this should give good coverage of all lighting conditions. This method also trains the model with a potential hidden bias. Because there are more cars parking during the day, it is more likely the model will learn that night time always means there is no car. The image on left shows a person walking and gets a different result than a nearly identical image during the day. The image on the right is included to balance the dataset to account for this bias.


The line separating the two groups is getting more complicated and would be very difficult to program using traditional methods.

These final examples show that the model must be able to account for unexpected events such as heavy rain or a car parked sideways. Handling unexpected data like this using the traditional methods would require significant rework.



In building this model, the programming stayed the same. It is all about the data and the curation of the datasets. The future of programming will be based on curating datasets and less about hand coding rules. I'm very excited for this change in programming and the new applications that can be made through it. We will need our tooling to catch up and I am excited to be working on it.
Questions, comments, concerns? Feel free to reach out to me at mcotton at mcottondesign.com