There are not many data problems that my answer doesn't start with clustering, and when the problem calls for clustering, kNN is my favorite method.
kNN is a well-used friend and a great starting point. As the problem size grows, you have to get into the nuance of kNN vs ANN. Let's start with some quick terminology.
kNN stands for K Nearest Neighbors; it is an algorithm for grouping data by looking at the items most common to them. If we had a dataset of animals that lists them by common attributes. Given a attributes about a new mystery animal, we could make a good guess at the type of animal by figuring out what its 16 nearest neighbors are.
(Footnote: In this example, k=16. This example value of k is arbitrary, and your results will vary with different values of k.)
One advantage of this method is that it is a great way to classify data in a highly explainable fashion. It is just math. There isn't a black box providing the classification; it is just your data, and you see exactly how it came to the answer. No training data or introduced bias from it.
When I say it is just math, I mean simple math. Loop through all the data and compute Euclidean distance to each, then sort and return k results.
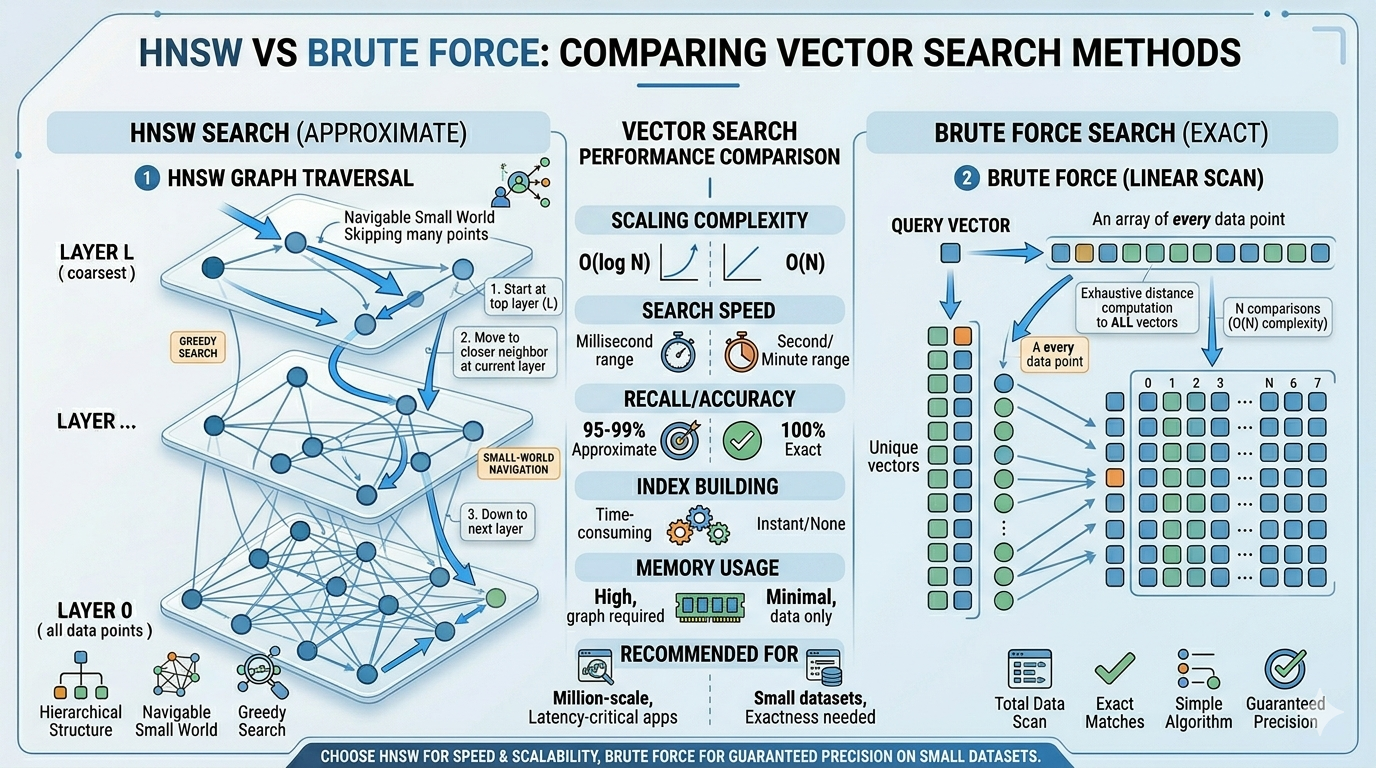
So what are the disadvantages? It can be horrifically slow as the data gets bigger. It is O(n). O(n) is bad. You have to brute force compare every item in the dataset.
This is where Approximate Nearest Neighbor comes in. With millions or billions of data points, there is no advantage to look at all of them if you only want k.
In a future post, we will look at my favorite ANN algorithm, but the short idea is you can get 95% of the results by over-sampling (for example, 500) and then brute forcing to get the final k neighbors.